内部-规模性能双杀OpenAI,Meta语音达LLaMA级里程碑!开源MMS模型可识别1100+语言

新智元报道
编辑:编辑部
【新智元导读】Meta的大规模多语言语音 (MMS) 项目将彻底改变语音技术,使用wav2vec 2.0的自监督学习,MMS将语音技术扩展到1100到4000种语言。
在语音方面,Meta又达到了另一个LLaMA级的里程碑。
今天,Meta推出了一个名为MMS的大规模多语言语音项目,它将彻底改变语音技术。
MMS支持1000多种语言,用圣经训练,错误率仅为Whisper数据集的一半。
只凭一个模型,Meta就建起了一座巴别塔。
并且,Meta选择将所有模型和代码开源,希望为保护世界语种的多样性做出贡献。

在此之前的模型可以覆盖大约100种语言,而这次,MMS直接把这个数字增加了10-40倍!
具体来说,Meta开放了1100多种语言的多语种语音识别/合成模型,以及4000多种语言的语音识别模型。
与OpenAI Whisper相比,多语言ASR模型支持11倍以上的语言,但在54种语言上的平均错误率还不到FLEURS的一半。
而且,将ASR扩展到如此多语言之后,只造成了非常小的性能下降。
论文地址:https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
保护消失语种,MMS把语音识别增加40倍
让机器具备识别和产生语音的能力,可以让更多人获得信息。
然而,为这些任务生成高质量的机器学习模型,就需要大量的标记数据,比如数千小时的音频以及转录——对于大多数语言来说,这种数据根本就不存在。
现有的语音识别模型,只涵盖了大约100种语言,在地球上的7000多种已知语言中,这只占很小一部分。令人担忧的是,在我们有生之年,这些语言中有一半都面临着消失的危险。
在Massively Multilingual Speech(MMS)项目中,研究者通过结合wav2vec 2.0(Meta在自监督学习方面的开创性工作)和一个新的数据集来克服了一些挑战。
这个数据集提供了超过1100种语言的标记数据,和近4000种语言的未标记数据。
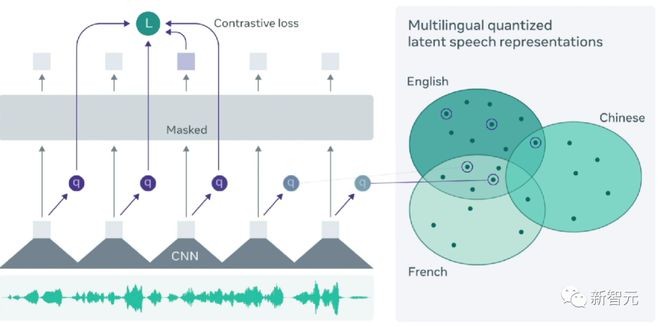
通过跨语言训练,wav2vec 2.0学习了多种语言中使用的语音单元
其中一些语言,如Tatuyo语,只有几百个使用者,而数据集中的大多数语言,以前根本就不存在语音技术。
而结果显示,MMS模型的性能优于现有的模型,覆盖语言的数量是现有模型的10倍。
Meta一向专注于多语言工作:在文本上,Meta的NLLB项目将多语言翻译扩展到了200种语言,而MMS项目,则将语音技术扩展到更多语言。
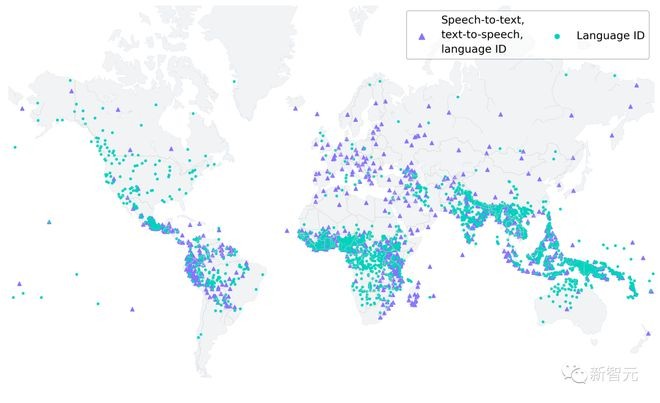
MMS支持1,107种语言的语音转文本和文本转语音,支持4,000多种语言的识别
圣经解决语音数据集难题
收集数千种语言的音频数据并不是一件简单的事情,这也是Meta的研究人员面临的第一个挑战。
要知道,现有的最大语音数据集最多也只涵盖了100种语言。为了克服这个问题,研究人员转向了宗教文本,如《圣经》。
这类文本已经被翻译成许多不同的语言,被用于广泛的研究,还有各种公开的录音。
为此,Meta的研究者专门创建了一个超过1100种语言的《新约》阅读数据集,平均每种语言提供32小时的数据。
再加上其他各种宗教读物的无标签录音,研究者将可用的语言数量增加到了4000多种。

在MMS数据上训练的自动语音识别模型,在FLEURS基准测试中,对男性和女性说话者具有相似的错误率
这些数据通常是由男性朗读的,但模型对男性和女性的声音表现得同样好。
并且,虽然录音的内容是宗教性的,但这并没有使模型过度偏向于产生更多的宗教语言。
研究人员分析认为,这是因为他们使用了连接主义时间分类方法,与用于语音识别的大语言模型或序列对序列模型相比,它的约束性要大得多。
模型越大,越能打?
研究人员首先对数据进行了预处理,以提高数据的质量,并使其能被机器学习算法所利用。
为此,研究人员在100多种语言的现有数据上训练了一个对齐模型,并将这个模型与一个高效的强制对齐算法一起使用,而该算法可以处理大约20分钟或更长时间的录音。
研究人员多次重复了这个过程,并根据模型的准确性进行了最后的交叉验证过滤步骤,为的是去除潜在的错误对齐数据。
为了使其他研究人员能够创建新的语音数据集,研究人员将对齐算法添加到了PyTorch中并发布了对齐模型。
目前,每种语言都有32小时的数据,但这并不足以训练传统的监督式语音识别模型。
这也就是为什么研究人员在wav2vec 2.0上训练模型,这样可以大大减少训练一个模型所需的标注数据量。
具体来说,研究人员在超过1400种语言的约50万小时的语音数据上训练了自监督模型——这个量比过去多了近5倍。
然后针对特定的语音任务,如多语言语音识别或语言识别,研究人员再对模型进行微调即可。
为了更好地了解在大规模多语言语音数据上训练的模型的表现,研究人员在现有的基准数据集上对它们进行了评估。
研究人员使用一个1B参数的wav2vec 2.0模型对超过1100种语言进行多语言语音识别模型的训练。
随着语言数量的增加,性能确实有所下降,但这种下降比较轻微——从61种语言到1107种语言,字符错误率只增加了约0.4%,但语言覆盖率却增加了18倍以上。
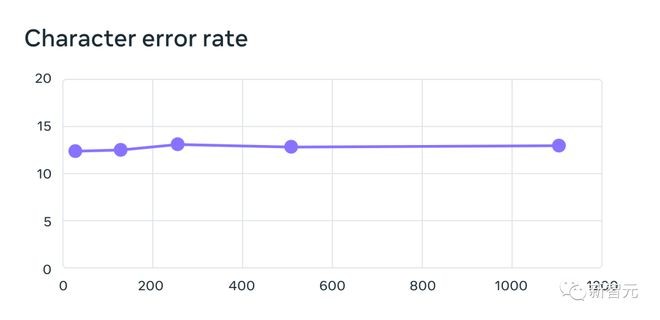
将每个系统支持的语言数量从61增加到1,107 时,使用MMS数据训练的多语言识别系统的61种FLEURS语言的错误率。错误率越高表示性能越低
在与OpenAI的Whisper进行同类比较时,研究人员发现,在Massively Multilingual Speech数据上训练的模型有将近一半的单词错误率,但Massively Multilingual Speech涵盖的语言是Whisper的11倍。
从数据中我们可以看出,与目前最好的语音模型相比,Meta的模型表现的真的非常不错。

OpenAI Whisper与Massively Multilingual Speech在54种FLEURS语言上的单词错误率对比
接下来,研究人员使用自己的以及现有的数据集,如FLEURS和CommonVoice,为超过4000种语言训练了一个语言识别(LID)模型,并在FLEURS LID任务上对其进行了评估。
事实证明,哪怕支持了将近40倍的语言数量,性能依然很能打。
在现有工作的VoxLingua-107基准上的语言识别准确性,支持的语言刚刚超过100种,而MMS则支持超过4000种语言
研究人员还为超过1100种语言建立了文本转语音的系统。
大规模多语种语音数据有一个局限性,那就是对于许多语言来说,它包含的不同说话者数量相对较少,通常只有一个说话者。
然而,这个特点对于建立文本到语音系统来说是一个优势,因此研究人员为超过1100种语言训练了类似系统。
结果表明,这些系统产生的语音质量还算不错。
未来属于单一模型
Meta的研究人员对这个结果感到很满意,但与所有新兴的AI技术一样,Meta目前的模型并不算完美。
比方说,语音到文本模型可能会误写选定的单词或短语,可能会导致冒犯性的或者不准确的输出结果。
同时,Meta认为,AI巨头的合作对于负责任的AI技术的发展至关重要。
世界上的许多语言都有消失的危险,而目前语音识别和语音生成技术的局限性只会加速这一趋势。
研究人员设想一个技术产生相反效果的世界,鼓励人们保持其语言的活力,因为他们可以通过说自己喜欢的语言来获取信息和使用技术。
大规模多语言语音项目是朝着这个方向迈出的重要一步。
在未来,研究人员希望进一步增加语言的覆盖面,支持更多的语言,甚至还会想办法搞定方言。要知道,方言对现有的语音技术来说可不简单。
Meta的最终目标是让人们能更容易地用自己喜欢的语言获取信息、使用设备。
最后,Meta的研究人员还设想了这样一个未来场景——靠一个单一的模型就可以解决所有语言的几个语音任务。
目前虽然Meta为语音识别、语音合成和语言识别训练了单独的模型,但研究人员相信,在未来,只需一个模型就能完成所有这些任务,甚至不止。
参考资料:
https://ai.facebook.com/blog/multilingual-model-speech-recognition/